Using URL alone to separate different visitors to a site as most visitor statistics programs do doesn't work. Using URL+agent with an activity timeout of 2 hours does.
Details
All web stats packages produce figures they describe as a visitor count.
What are they based on, and how meaningful are they?
If your site issues cookies, then your count can be reasonably accurate. Of course, some users set their browsers to reject cookies, because they invade privacy when used by multisite sources such as doubleclick. Some users that accept cookies delete them after each session as I do. Still others use shared computers at internet cafés or libraries. But, most probably don't.
However, given the complexity of the code required to handle people who cannot accept cookies when you are an information provider and want everyone to see your pages, or just on the principle of freedom of all, most sites (including mine) don't use them. So, the simplest visitor counts just look at the requesting URL; if no request is made from one for a timeout period, the next time it's a new visitor. Most choose half an hour as the timeout period.
First, reliable stats have to eliminate robots. Why? See Search Engines: costs vs. benefits, where I found that robots had risen to 45% of my traffic by the summer of 2007. Robots don't buy things and they aren't interested in what you have to say. Any procedure that doesn't eliminate them from stats is not relevant. All measurements that follow do. (list of search terms)
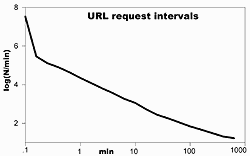
Graph 1 shows the distribution of average intervals between successive html page requests from each URL over a three year period (1Mar2005-29Feb2008). (For the method, see What is your Server's Real Uptime.) Excepting times under 0.22 minutes (mostly due to viewing accelerators that load all pages referred to by the current page in advance) the distribution is a straight line: there is no time that can statistically be identified as a boundary between a single visitor and multiple visitors. Any procedure using solely URLs and a timeout is not reliable.
There is another problem with using just URLs to measure traffic: major ISPs assign their IP addresses dynamically because they have far more users than IP addresses. So, a user who is inactive for a period of time will get a new address for their next query, and a new user may then get the same URL. How prevalent is this?
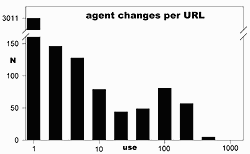
There is a second way that visitors identify themselves besides URL: the agent field that identifies their browser and operating system. Graph 2 shows the number of times the agent changed from each of 3600 URLs (the memory limit of my 16-bit compiler). 84% of the URLs were used by only one agent over the three years, but a significant fraction changed agents over 100 times. Any procedure using solely URLs to identify visitors is not reliable.
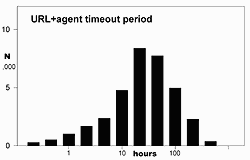
Graph 3 shows the length of time between requests with different agents from these URLs. URL+agent seems capable of defining a visitor over several hours. (Note that this shows the timeouts between requests, not total user session time.)
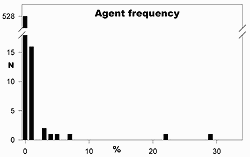
Of course, most people leave browsers in default configuration and use the same operating systems. Most institutional viewers use a system-shared browser. How reliable is the notion that URL+agent equals a unique visitor? Graph 4 shows the frequency of occurence of agent strings over the three years. Two agent strings account for half of all accesses. So, a lot of the times that users change, the agent won't.
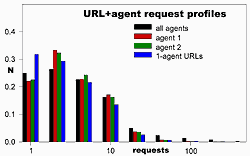
How many URLs are used by these most common agent strings? Both were used by over 32767 URLs (the 16 bit limit again). Graph 5 shows the distribution of the number of requests made by each URL over the three year period using these agent strings, as well as those of URLs with unchanged agent. Apart from a slight tendency for single-agent URLs to make only a single request, they all have similar profiles - all can be treated the same way. And, the common agents use so many URLs that the probability of two simultaneous different visitors using the same URL+agent is very small.
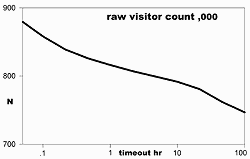
Last, we need to choose the optimum user timeout. Graph 6 shows my results compared to the inactive time chosen. Clearly, for my site, it doesn't matter much. There is a slight leveling between 1 and 10 hours, but not much.
Graph 6 confirms what is shown by analysis of the refer field, that only 19% of my page hits come from my own pages, and some of these are due to browser accelerators. According to this, almost all of my visitors come direct to one page from a search engine, and don't follow up directly to other pages at my site.
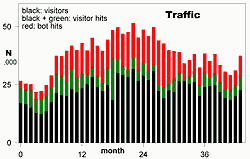
For many sites, this last will not be true. However, I suspect that very few visitors appear, spend more than 2 hours during one on-line session elsewhere, then return to view another page. The data shown in graph 3 shows that the URL+agent model will underestimate visitor sessions by only a small amount if this timeout period is chosen. Graph 7 shows the result for my site.
 1
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7