Summary
For a non-commercial information provider, search engine costs are the bandwidth generated on a
site by search robots that has to be paid for. Their benefits are the user page reads that result.
Search bots have become so numerous in recent years that they are a major drain on site resources
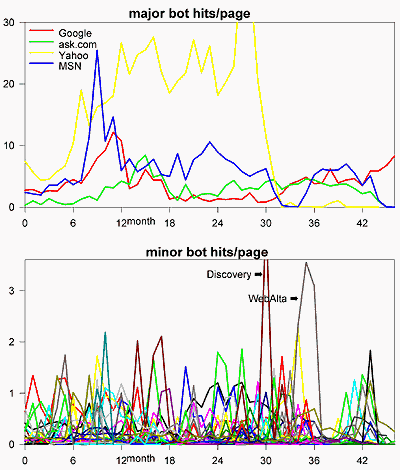
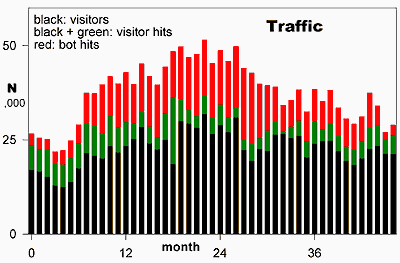
while most provide almost no benefit in return. Identified bots accounted for 45%
of my site hit and bandwidth costs by July 2007. This ratio continues in 2018, when I switched
to a host that separates known bots from real viewers. Yahoo remains by far the worst bot abuser.
A solution available to all users is to use a robots.txt file to exclude all bots but Google. Bot hits decrease to a small fraction of those to an unprotected site, and visitor count decreases only slightly.
Details
Here were some of my search engine numbers when I started this project in July 2007:
| Active html pages: 293
Total page hits: 42870 User page views/mo (known bots removed): 23387 | |||
| search engine | bot hits/mo | user hits/mo | benefit:cost |
|---|---|---|---|
| Yahoo | 10323 | 874 | 1:12 |
| Ask | 1359 | 89 | 1:15 |
| MSN | 1358 | 184 | 1:7 |
| 598 | 8499 | 14:1 | |
| Twiceler | 473 | 0 | 0 |
| Voila | 224 | 0 | 0 |
| Seekport | 149 | 0 | 0 |
| Picsearch | 87 | 48 | 1:2 |
| Ichiro | 83 | 0 | 0 |
| Cazoodle | 78 | 0 | 0 |
| Gigablast | 62 | 60 | 1:1 |
| Naver | 52 | 27 | 1:2 |
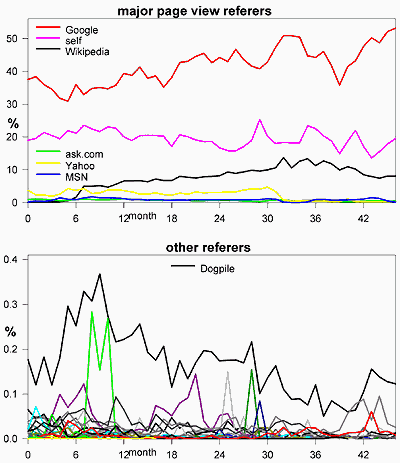
42% of my user views came from Google, and you can't beat their benefit:cost ratio. But all the other engines above except Gigablast were a net loss to me.
How do you get rid of bots that make excessive requests? The simplest way is to set up a robots.txt file in your root server directory containing:
User-agent: Slurp Disallow: /to get rid of Yahoo's main agents. Repeat for other bots as appropriate. If, after reading this page, you want to get rid of the whole lot except Google, as I have, use:
User-agent: Google Disallow: User-agent: * Disallow: /
Data collection method
I've been archiving page logs since 1 March 2005. For each GET *.html entry in my logs, I
search first for bots (case insensitive) with strings similar to these:
Ask: teoma OR minefield
GenieKnows: geniebot
Google: googlebot
Ichiro: ichiro
MSN: msnbot OR msrbot OR msiecrawler OR lanshanbot
Naver: naverbot OR yetibot
Sproose: crawler@sproose
Yahoo: slurp OR yahooseeker OR Yahoo-MMCrawler
miscellaneous bots: bot.htm OR bot" OR crawl OR spider
Once these entries are removed, I search for a user hit from the engine:
Ask: .ask.
GenieKnows: genieknows
Google: .google. OR earthlink OR aolsearch
Ichiro: .goo. OR .nttr.
MSN: msn.co OR search.live
Naver: naver
Sproose: sproose
Yahoo: yahoo OR alltheweb OR altavista.com
This method relies on the refer field of the user log. It has limitations: people can turn refer off in some browsers, proxy or content filters can interfere with the refer field, and page caching reduces recorded user views but not bot hits. Another problem with pinning down searchbot results is metasearchers who check several databases to come up with their results and give preference to pages that are in many bases. A final problem is that some bots, open source ones in particular, are run independently by many users; identification of user views is often not possible with these.
So, results of this method have to be investigated for consistency. To start, here are the referers that had an average of 10 bot+user hits/mo or more over the study period, in order of their total activity on my site:
There are hundreds of people who have set up open source crawlers under hopeful names, who have rapidly discovered the huge resources needed for even the most focussed database, and who have vanished. Looking for crawl, bot.htm, bot" and spider after all other checks gets almost all of them. Dumped into a file, a refer field sort enables new ones to be spotted and checked.
Experimental Action
Yahoo was disallowed Aug07 (the graph below shows why!), MSN Oct07.
The first result: site hit and bandwidth costs due to bots went from 45% in Jul07 to 27% over Nov07-Jan08. Here are the expectations for Nov07-Jan08 from a line fit Mar05-Aug07 and the actual:
| source | expected | actual | % change |
|---|---|---|---|
| total user hits | 33910±1980 | 28300 | -16.5 |
| Google % | 46.29±1.35 | 51.20 | +10.6 |
| Wikipedia % | 12.16±0.73 | 12.42 | +2.1 |
| Yahoo % | 3.43±0.54 | 0.60 | |
| MSN % | 0.91±0.37 | 0.07 |
The expected loss in viewer hits from blocking Yahoo and MSN is 3.7%. The actual loss seems to be about 16% from the total hit activity, 11% based on Google and 2% on Wikipedia. The mean of these three is 9.7%. The loss in user views seems about 3x that expected.
Metasearch engines (ones that check many databases) require almost no investment to set up, so come and go. Dogpile is the only significant one I have been able to identify on my site (0.2% of viewers). Only three of the 27 I have located hit more than 100 pages each over the 34 month period; most had fewer than 10. They are minor players.
18% of user hits came from my own pages, so 84% of user hits have been traced to 5 referring sources. Possible modifications of Yahoo+MSN refer fields can only account for ±0.6% of any change, so most people don't do it.
MSN was re-enabled mid-Feb08 to see if the effects of MSN and Yahoo could be separated. The result: all the unexpected loss in user hits was due to Yahoo. It appears that only a third of user views due to Yahoo actually came from a Yahoo site or from a metasearcher that says they use Yahoo. So, its actual benefit:cost is about 1:4.
As a final experiment, I allowed Google, Turnitin and archive.org and disallowed everything else mid Nov08 as described above. The result - a gratifying loss of useless bot hits and almost no loss of users. I recommend it.
Unfortunately, this project was blown out of the water by a dishonest registrar who stole my domain name early November 2009. I hope the results to this point give you some useful information on how many bots there are out there that aren't worth their keep, and how to deal with them.
user-agents.org is a useful resource for identifying searchbots, but havn't gone into search results. Colossus has large lists of search sites.
John Sankey
other notes on computing